
AI SFAを検討中の方へむけて、本記事ではAIが営業で得意・不得意な領域から、成果を出す前提となる顧客データ管理(名寄せ、活動履歴の粒度、商談ステージ、失注理由)までを整理します。結論として、AIの精度と定着は「入力負担を減らす自動収集」「CRM/MAとのデータ統合」「パイプライン可視化とKPI設計」「権限・セキュリティを含む運用設計」で決まることがわかります。
1. AI SFAを検討する人が最初に知るべきこと
AI SFAを検討するときに最初に揃えるべきなのは、製品比較表よりも先に「AIに何を任せ、何を人が判断するのか」という期待値の線引きです。ここが曖昧なまま導入すると、現場は「入力が増えた」と感じ、マネージャーは「予測が当たらない」と感じ、経営は「投資対効果が見えない」と感じやすくなります。
本記事でいうAI SFAは、単に「AI機能が付いたSFA」ではなく、営業活動・顧客接点・商談情報をデータとして扱い、AIで意思決定と実務を支援するSFA運用までを含みます。つまり、ツール選定だけでなく、入力・連携・運用・データ設計まで含めて初めて効果が出ます。
AI SFAの成果は、大きく次の2種類に分かれます。
- 現場の生産性を上げる(作業を減らす):記録の自動化、要約、次アクション案、提案準備など
- マネジメントの精度を上げる(判断を良くする):パイプライン把握、見込みの評価、リスク兆候の早期検知など
この章では、AIの得意・不得意と、AI活用の前提となる顧客データ管理の考え方を整理し、「AI SFAで何ができて、何ができないのか」を誤解なく掴める状態を作ります。
1.1 AIが得意なことと不得意なこと
AI SFAとひとくちにいっても、実装されているAIには複数のタイプがあります。代表例は、生成AI(文章生成・要約)と、予測・分類(機械学習によるスコアリング)です。同じ「AI」でも、得意な仕事と失敗の仕方が違うため、先に整理しておくと判断がブレません。
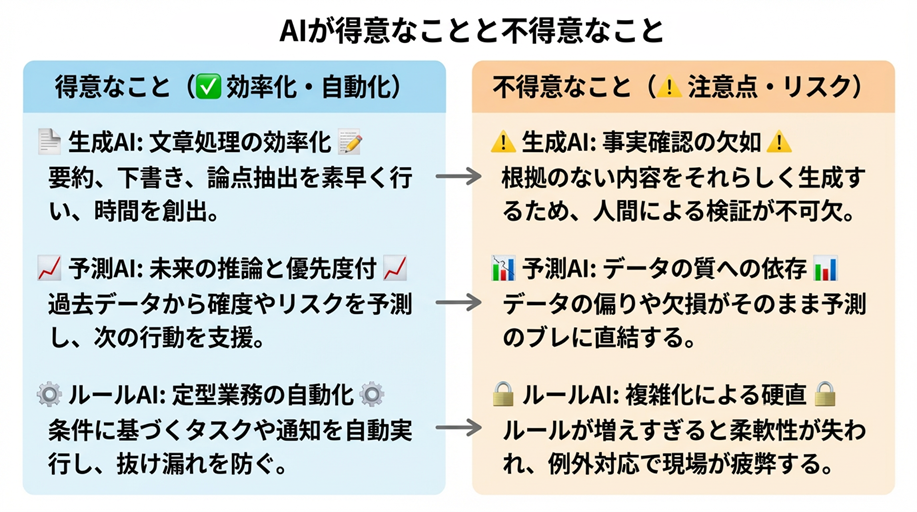
- 情報量が多く、人が毎回ゼロから整理するのが非効率な作業(通話・メール・商談メモの要約、論点整理、ToDo抽出)
- 一定の型に落とせる作業(提案書の目次案、ヒアリング項目のチェックリスト、稟議用の要点整理)
- 「見落とし」を減らしたい作業(対応漏れの兆候、停滞案件の検知、期限超過のアラート)
一方で、AIに任せきりにすると危険になりやすいのは、次のような領域です。
- 社内の方針・採算・リスクを踏まえた最終判断(値引き判断、契約条件、与信、優先順位の確定)
- 一次情報が存在しない/入力されていないものの推測(実際の決裁者、競合状況、温度感などを「それっぽく」埋める)
- 定義が揺れているKPIやステージの評価(組織内で基準が揃っていないと、AIは整合した学習ができない)
ここで重要なのは、AIの精度を「AIの賢さ」だけの問題にしないことです。AI SFAの成否は、データの取り方・定義・更新頻度・例外処理の設計に強く依存します。AIは魔法ではなく、運用が整った組織ほど「効く」道具です。
AI SFAを選ぶ・設計する際は、次の3つの問いで要件を言語化すると失敗が減ります。
| 問い | 決めること | 具体例 |
|---|---|---|
| AIに「生成」させたいのは何か | 文章化・要約・テンプレ化の対象 | 商談メモ要約、引き継ぎ文、提案骨子、メールドラフト |
| AIに「予測」させたいのは何か | スコアや優先度の対象 | 停滞案件の検知、確度の補助、次アクション候補 |
| 人が「責任を持つ」判断は何か | 最終決定の境界線 | 金額・条件、顧客への確約、受注見込みのコミット |
この線引きを先に作っておくと、AI SFAの導入後に「AIが提案したからそうした」「AIが当たらないから使わない」という両極端を避け、AIを“補助輪”として定着させる設計ができます。
1.2 AI活用の前提になる顧客データ管理
AI SFAの検討で最も見落とされやすい前提が、顧客データ管理です。AIはデータがないところから価値を生みません。言い換えると、AI SFAの投資対効果は「入力を増やす」ことではなく、「自然に集まる・使えるデータ」を増やすことで最大化します。
AI活用の観点で、顧客データは大きく3層に分けて考えると整理しやすくなります。
| データ層 | 内容 | AI SFAでの主な用途 | 崩れやすいポイント |
|---|---|---|---|
| マスタ(誰・どの会社) | 企業名、部署、担当者、役職、連絡先、関係性 | 名寄せ、重複排除、担当者変更時の引き継ぎ、組織図の把握補助 | 表記揺れ、同名企業、担当者の異動・退職、個人の複数連絡先 |
| 活動(いつ・何をした) | メール、電話、会議、訪問、議事録、次アクション、期限 | 要約、ToDo抽出、停滞検知、フォロー漏れ防止、会話の論点整理 | 記録漏れ、粒度のバラつき、主観だけのメモ、時系列の欠落 |
| 商談(何を売る・いくら・いつ) | 案件名、金額、見込時期、ステージ、確度、競合、失注理由 | パイプライン可視化、予測の補助、勝ち筋・負け筋の分析 | ステージ定義の不統一、金額のもち方の違い、失注理由の曖昧さ |
この3層のうち、AIで成果が出やすい順に「活動 → 商談 → マスタ」だと誤解されがちですが、実務では逆です。マスタが崩れていると活動も商談も紐付かず、AIの分析対象が分裂するため、まず「誰のデータなのか」を安定させる必要があります。
AI前提の顧客データ管理で、導入初期に決めるべき最低限の方針は次のとおりです。
- 顧客(個人)と企業(法人)を別オブジェクトとして扱う(「会社」と「人」を混ぜない)
- 名寄せの基準を一つに寄せる(企業名表記・法人番号・ドメインなど、組織に合うキーを決める)
- 活動履歴は“後から検索できる形”で残す(日付、相手、手段、要点、次アクションが欠けない)
- 商談ステージと確度の意味を統一する(個人の感覚で更新しない)
また、AI SFAでありがちな落とし穴が「入力項目を増やしてデータを揃えようとする」ことです。必要なのは、入力を増やすことではなく、入力せずに集まるデータを増やし、入力が必要な項目は最小にすることです。
| データ収集のやり方 | 短期の見え方 | 中長期の結果 | AI SFAの観点 |
|---|---|---|---|
| 入力項目を増やして埋めさせる | 管理項目は増える | 入力疲れで空欄が増え、最新でなくなる | 学習データが歯抜けになり、提案や予測の品質が不安定になる |
| 自動収集を増やし、入力は最小化する | 立ち上がりに設計が必要 | 活動が自然に蓄積し、継続的に鮮度が保たれる | AIが扱える時系列データが増え、要約・検知・推薦が安定する |
AI SFAの検討時点で、次のチェックリストに一度答えると、データ起因の失敗を先回りできます。
- 顧客データは「会社」と「担当者」が分離され、紐付いているか
- 同一企業の表記揺れ(例:株式会社の有無、全角半角、旧社名)を吸収できているか
- 活動履歴(メール・通話・面談)が、案件や顧客に紐付く設計になっているか
- 商談のステージが人によって意味が違う状態になっていないか
- 失注理由が「その他」で埋まりやすい設計になっていないか
この章の結論はシンプルです。AI SFAの導入検討は、機能の多さではなく、データが集まり、整い、使われ続ける設計になっているかから逆算して進めると、現場・マネージャー・経営の全員が納得しやすい形になります。
2. 現場が楽になるAI SFAの要件
AI SFAは「AIが賢いこと」よりも、営業担当者が日々の営業活動の中で、無理なくデータが溜まり、溜まったデータがそのまま成果に返ってくることが最優先です。現場が楽になる要件は、大きく分けて「入力負担を限りなく小さくする」「商談準備と提案作成を短縮する」「担当変更に強いナレッジを残す」の3つに整理できます。
ここでのポイントは、AIの機能一覧を増やすことではありません。現場の時間を奪う“作業”を減らし、顧客対応に使える時間を増やすために、SFAのデータ設計・連携・UI/UX・運用ルールまでを要件として具体化することが重要です。
2.1 入力ゼロに近づける自動収集
現場がSFAを使わなくなる最大の理由は、入力が「二度手間」「評価のための作業」「顧客価値に直結しない」と感じられることです。AI SFAで最初に狙うべきは、入力の“お願い”を減らし、営業担当者の行動から自動で活動履歴が作られる状態です。
ただし、自動収集は「何でも集めれば良い」わけではありません。現場が見るべき情報が埋もれないように、自動で入る情報の種類・粒度・紐づけ先(リード/取引先/商談/担当者)を揃えることが要件になります。
| 自動収集の対象 | SFAに残すべき最小項目(例) | 現場が楽になる効果 | 要件の注意点 |
|---|---|---|---|
| メール(送受信) | 件名、送受信日時、宛先/CC、本文(必要に応じて)、添付有無、紐づく顧客・商談 | 「誰と何を話したか」を後追い入力しなくて済む | 自動紐づけの精度が低いとノイズになるため、名寄せルールと例外処理が必要 |
| カレンダー(予定) | 会議名、日時、参加者、場所/URL、目的(任意)、紐づく顧客・商談 | 訪問・オンライン商談の記録が自動で残り、活動量が可視化される | 社内会議まで取り込むと混ざるため、フィルタ条件(外部参加者の有無など)を要件化する |
| オンライン商談(Web会議) | 会議URL、参加者、録画/議事録の有無、決定事項、ToDo、次回アクション | 議事録作成・要点整理・ToDo化が短縮される | 録音・録画の取り扱いは社内ルールに合わせ、同意取得フローを設計する |
| 電話(発着信・通話ログ) | 発着信日時、相手先、通話時間、メモ、次アクション | 架電/受電の活動が自動で残り、日報のための入力が減る | 個人携帯・IP電話など環境差が出るため、現実的な対応範囲を決める |
| 名刺(交換・取り込み) | 氏名、会社名、部署、役職、メール、電話、名刺交換日、担当者 | 初回接点の登録が一気に終わり、リード登録の摩擦が減る | 会社名の表記ゆれが起点で重複が増えやすく、名寄せ方針が不可欠 |
| 自社Webフォーム(問い合わせ) | 流入元、問い合わせ内容、検討時期、課題、同意状況、紐づく担当 | 手作業転記が不要になり、初動が早くなる | 「誰が対応するか」の自動割り当てルールまで要件に含める |
自動収集を「現場が楽」につなげるために、次の要件を明確にしておくと運用が崩れにくくなります。
- 自動で入る情報と、手入力が必要な情報の線引き(例:商談の確度・金額は手入力、活動履歴は自動など)
- 自動紐づけの優先順位(取引先→担当者→商談の順に紐づける、曖昧なら保留箱に入れる等)
- ノイズを減らすフィルタ条件(外部ドメインが含まれるメールのみ、特定キーワードのみ等)
- 後から直せる仕組み(誤紐づけの簡単な修正、まとめて整理できる画面、修正ログ)
結果として、営業担当者にとっては「入力するためにSFAを開く」のではなく、顧客対応をしていたら勝手にSFAが整っていく状態に近づきます。この状態を作れているかが、AI活用以前にAI SFA導入の成否を決めます。
2.2 提案書作成と商談準備の支援
AI SFAが現場に歓迎されるかどうかは、提案書・見積・メール文面・商談準備といった“締切のある作業”が早くなるかで決まります。特にBtoB営業では、商談前後の作業(情報収集、仮説づくり、提案構成、社内確認)が積み上がり、担当者の可処分時間を圧迫します。
ここでの要件は「AIが文章を書ける」ではなく、SFAにある顧客情報・過去商談・接触履歴を踏まえ、いま必要なアウトプットが一発で出ることです。データが散らばったままだと、AIが作る内容も薄くなり、結局人が調べ直すことになります。
| 現場が欲しい支援 | AI SFAのアウトプット例 | 前提データ(SFA/連携) | 要件(品質を担保する条件) |
|---|---|---|---|
| 商談前の情報整理 | 直近のやり取り要約、決裁者・関係者マップ、未解決論点、次回の確認事項 | メール、会議ログ、活動履歴、案件メモ、組織図(ある場合) | 要約の根拠となる元データにすぐ戻れる(引用元が追える) |
| ヒアリング設計 | 業界別の質問リスト、想定課題仮説、検討プロセスの確認項目 | 過去の勝ちパターン、失注理由、商談ステージ履歴 | 自社の営業プロセスに沿ったテンプレートを適用できる |
| 提案骨子づくり | 提案構成案、想定反論と回答、競合比較の観点、導入スケジュールたたき台 | 提案書ナレッジ、製品情報、類似案件の提案・稟議情報 | 最新情報に基づく(古い価格・仕様を出さない)ための更新フローがある |
| フォローアップメール | お礼メール、議事録送付文、宿題の整理、次回日程打診文 | 会議メモ、ToDo、次回アクション、相手の役職・関心 | 社内のトーン&マナーと法務・コンプラ方針に沿った文面テンプレート |
| 見積・条件整理 | 必要情報チェックリスト、条件の抜け漏れ指摘、社内承認用の説明文の下書き | 過去見積、値引き理由、承認フロー、案件の背景 | 権限のある人だけが閲覧・生成できる範囲を制御できる |
提案書作成・商談準備支援を「現場が楽」にするための要件を、もう一段具体化すると次の通りです。
- 1クリックで“商談ブリーフ”が作れる(顧客概要、接触履歴、前回決定事項、目的、想定アジェンダ、次アクションまでをまとめる)
- 営業担当者が直した箇所を次回に活かせる(生成物の編集履歴、良い表現・良い構成の再利用)
- 提案の中身が“自社の型”に寄る(業界別テンプレート、商材別プレイブック、価格・契約条件の注意点などを参照できる)
- 生成結果の根拠が追える(どの活動履歴・どの過去案件を参照したかが分かる)
- 現場のチェック工程が短くなるUI(差分表示、社内確認者への共有、コメント、タスク化が速い)
「提案をAIに書かせる」こと自体が目的になると、現場は逆に疲れます。目指すべきは、商談の勝ち筋に関係する準備だけが短縮され、品質が安定することです。
2.3 担当者の引き継ぎを強くするナレッジ化
営業組織では、担当変更・退職・異動は必ず起きます。そのときに失注や関係悪化が起きるのは、SFAに「数字」や「結果」しか残っておらず、意思決定の背景、相手のこだわり、関係者の力学、NG事項が残っていないことが原因になりがちです。
AI SFAで引き継ぎを強くするには、単に「メモを残す」では不十分です。散らばった情報を“検索できる知識”に変え、次の担当者がすぐ動ける状態に整えることが要件になります。
| ナレッジ化する対象 | 残すべき内容(例) | AI SFAでの使い方 | 要件(運用が回る条件) |
|---|---|---|---|
| 顧客の意思決定情報 | 決裁者、稟議の流れ、重視指標、導入障壁、過去の購買理由 | 次回提案の論点抽出、商談ステージ判断の補助 | 所定の項目に“短文で”入れられる(長文だと更新されない) |
| 会話の要点 | 決定事項、宿題、相手の懸念、競合の存在、導入時期 | 議事録要約、ToDo自動生成、次回アジェンダ提案 | 要約だけでなく、元の会話ログやメモへ戻れる |
| 提案・資料の履歴 | 提案書、見積、比較表、説明資料、カスタマイズ案 | 類似案件の流用、勝ちパターンの抽出 | 最新版管理(重複・古い版の混在を防ぐ) |
| 失注・停滞の学び | 失注理由、停滞理由、決め手不足、次回の打ち手 | 打ち手の推薦、リスク検知、再アプローチのタイミング提案 | 「その他」だらけにならない分類設計(選択+補足の併用など) |
| 社内の対応履歴 | 法務確認、セキュリティチェック、特記事項、例外承認 | 手戻り防止、承認ルートの短縮 | 閲覧権限を適切に分け、必要な人にだけ届く |
現場の引き継ぎを本当に楽にするためには、「ナレッジの入力を増やす」のではなく、活動の結果としてナレッジが自然に整う設計が必要です。具体的な要件は次の通りです。
- 商談ごとの“要点”が自動で集約される(活動履歴から、決定事項・懸念・ToDoを抽出して商談ページにまとまる)
- 引き継ぎ時に読むべき情報が最短で出る(「この顧客の重要人物」「直近の未解決論点」「次回アクション」などの定型ビュー)
- 検索が強い(「値引きで揉めた」「稟議が長い」「競合が強い」など、現場の言葉で探して辿り着ける)
- 属人メモを“チーム資産”に変換できる(個人のメモを共有可能な項目に移す、共有前提のテンプレートを用意する)
- 更新されない情報を前提にしない(古い前提が残ると事故になるため、重要項目には更新日・更新者が残る)
AI SFAは、ナレッジ共有を「気合い」から解放できます。ただしそのためには、現場が“入力したくなる”のを待つのではなく、現場の動きから勝手にナレッジが増える仕組みを要件として先に固めることが欠かせません。
3. 経営とマネージャーが得をするAI SFAの要件
AI SFAを「現場の入力を楽にするツール」としてだけ捉えると、導入効果が局所最適になりがちです。経営・営業責任者・マネージャーにとっての本質的な価値は、売上(受注)に直結する意思決定を、データに基づいて速く・正確に行える状態を作ることにあります。
そのためには、AIがレポートを自動生成する以前に、SFA側で「判断できる形」に情報が整理され、運用に耐えることが必要です。ここでは、経営とマネージャーが成果を得やすくするためのAI SFA要件を、①パイプライン可視化と予測、②営業プロセス標準化、③KPIとダッシュボード設計の観点で具体化します。
3.1 パイプラインの可視化と予測精度
経営とマネージャーが最初に求めるのは、「今月(四半期)の着地がどうなるか」を、根拠とセットで説明できる予測です。AI SFAの価値は、単なる合計の集計ではなく、商談の進捗、停滞、失注リスクを検知して、パイプラインの健全性を立体的に可視化できる点にあります。
AIで予測精度を上げるには、確度(主観)だけに頼らず、客観的なシグナルをSFA内に残せることが重要です。たとえば、商談ステージの前進、意思決定者との接点、見積提示の有無、次回アクションの具体性、一定期間の停滞などは、予測の説明可能性を高める材料になります。
一方で、AIの予測が「当たる/外れる」だけでは、現場は納得しません。マネージャーにとって必要なのは、なぜその予測になったのか(根拠)と、今何を打てば良いのか(打ち手)です。したがって、AI SFAには予測結果の提示だけでなく、要因分解やリスクの早期警告、修正アクションの提案までを一連で支援できる設計が求められます。
| データ要素 | SFAでの具体例 | 経営・マネージャーのメリット | 運用上の注意 |
|---|---|---|---|
| 商談ステージの遷移履歴 | いつ、どのステージからどこへ進んだか(停滞期間も含む) | 停滞・前進のパターンから、着地のリスクを早期把握できる | 「なんとなく更新」を防ぐために、ステージ移動の条件(Exit Criteria)を決める |
| 次回アクションの具体性 | 次回面談日時、提案内容、宿題、決裁者同席の予定など | 案件レビューが「進捗確認」ではなく「打ち手検討」になる | 自由記述だけにせず、最低限の構造化(期限、種類、相手)を持たせる |
| 関係者情報(意思決定構造) | 決裁者、推進者、反対者、利用部門、購買部門の有無 | 属人的な読みを減らし、支援すべき案件を見極めやすい | 個人情報の取り扱い方針に沿って、閲覧権限と保存項目を統制する |
| 見積・提案の提出状況 | 見積提出日、提案書提出日、提案パターン(A/B) | 「提案済みなのに動かない」など、要注意状態を把握できる | ファイル管理が分散すると把握できないため、参照先の統一(リンク管理など)を行う |
| コミュニケーション量と反応 | メール往復、会議回数、返信の有無、議事メモの有無 | 熱量が落ちている商談をAIが検知し、早期介入できる | 量だけで評価すると逆効果になり得るため、「目的のある接点」に寄せる |
| 金額・期間・確度の変動 | 見込金額の増減、契約開始時期の後ろ倒し、確度の変動 | 予実差の原因(単価・件数・時期)を分解しやすい | 変更履歴を残さないと分析できないため、履歴保持を前提に設計する |
また、経営視点では「全社の予測」に加えて、予測のブレがどこから生まれているか(組織・商材・チャネル・担当者・ステージ)を特定できることが重要です。AI SFAは、予測の数値だけを提示するのではなく、予実差の分解や、ボトルネックの箇所(例:特定ステージでの停滞、失注率の上昇、提案提出から決裁までの長期化)を一目で追えることが要件になります。
最後に、予測は「当てること」がゴールではありません。AI SFAの評価軸は、予測により意思決定が前倒しされ、打ち手(値引き方針、役員同席、技術支援、リソース再配分)が具体化されることです。ここが設計されていないと、AIが高機能でも経営の実利につながりません。
3.2 営業プロセスの標準化
マネージャー業務が重くなる最大の理由は、案件レビューが「人別・案件別の属人的な会話」になり、再現性のある型に落ちないことです。AI SFAは、トップ営業の暗黙知を組織知に変え、誰が担当しても一定品質の営業活動が進む状態を作るときに最も効果を発揮します。
営業プロセスの標準化で重要なのは、現場の自由度を奪うことではなく、「最低限揃えるべき判断材料」と「次に取るべきアクションの選択肢」を揃えることです。AIを前提にするなら、ステージごとに必要な情報と次アクションの候補(ネクストステップ)を設計し、入力負荷を増やさずに実行を促す必要があります。
具体的には、AI SFAには以下のような標準化支援が求められます。
- ステージ定義とExit Criteriaを運用できること(例:決裁者に提案済み、要件が合意済み、見積提出済みなど、ステージ移動の条件を明確化)
- 商談の「型」をテンプレート化できること(業界別のヒアリング項目、提案骨子、想定質問、競合対策など)
- 活動の抜け漏れを検知して、次アクションを提案できること(例:一定期間「次回予定なし」をアラート、決裁者未接触を検知)
- 案件レビューを短時間で高密度にする要約・論点抽出ができること(直近の活動、相手の関心、障害、意思決定構造の変化を整理)
| 標準化の対象 | 具体例 | マネージャーの得 | AI SFAに求めたい支援 |
|---|---|---|---|
| 商談運用(進め方) | 初回ヒアリング→要件整理→提案→見積→稟議→契約の基本フロー | 案件の状態把握が速くなり、介入ポイントが明確になる | ステージに応じたチェックリスト、要約、次アクション提案 |
| 提案品質 | 提案の構成、導入効果の示し方、比較表の持ち方 | 属人的な提案力の差を縮め、勝ち筋を再現しやすい | 過去の勝ちパターン参照、提案骨子生成、類似案件検索 |
| 案件レビューの論点 | 意思決定者、競合、予算、導入時期、リスク、次の障害 | 会議が「報告の場」から「意思決定の場」になる | 論点の自動抽出、未記入項目の指摘、リスクスコア |
| 引き継ぎ・共同対応 | 休職・異動・分業時の情報共有、技術同席時の前提共有 | 担当交代で失注しにくくなり、組織として受注を守れる | 時系列サマリ、重要人物と合意事項の抽出、関連資料の紐付け |
標準化を成功させるコツは、ルールを増やすことではなく、標準に乗るほうが「速く成果が出る」「叱られない」「迷わない」と現場が感じる設計にすることです。AI SFAが、入力を強制するのではなく、行動の質を上げる方向に働くと、マネジメントの負荷が下がりながら成果に近づきます。
3.3 KPIの定義とダッシュボード設計
経営とマネージャーがAI SFAを「得する仕組み」に変える最後の鍵が、KPIとダッシュボードです。KPIは多すぎると現場が動けず、少なすぎると原因が追えません。AI SFAでは、成果KPI(遅行指標)と、成果を動かす先行指標をセットでもち、同じ画面で因果を追えることが重要です。
また、KPIは「名称」だけでは運用できません。定義が曖昧だと部署や担当者で解釈がズレ、ダッシュボードが信用されなくなります。AI前提では、少なくとも以下が揃っている状態が望ましいです。
- KPIの定義(何を1件と数えるか)と、計算式が明文化されていること
- 更新頻度(リアルタイム/日次/週次)と、利用シーン(週次会議/月次締め)が一致していること
- 数字の責任者(誰が改善のオーナーか)が決まっていること
- ドリルダウン(全社→部門→チーム→個人→案件)でき、原因特定まで到達できること
| カテゴリ | KPI例 | 定義・計算例 | ダッシュボードで見たい観点 |
|---|---|---|---|
| 成果(遅行指標) | 受注金額、受注件数、粗利 | 当月の受注合計、または四半期累計 | 予算比、前年同期比、着地見込み(予測) |
| パイプライン健全性 | パイプライン総額、ステージ別金額、加重パイプライン | ステージ別の見込金額合計、確度で加重した合計 | 偏り(特定ステージに滞留していないか)、不足(目標に対して足りているか) |
| 転換率(ボトルネック特定) | ステージ転換率、提案→受注率 | 次ステージへ進んだ件数 ÷ 当該ステージの件数 | どのステージで落ちているか、改善施策の前後比較 |
| スピード(リードタイム) | 初回接触→受注日数、ステージ滞留日数 | 受注日-初回接触日、または各ステージの滞在日数 | 長期化の兆候、停滞案件の抽出、商談の優先順位付け |
| 活動(先行指標) | 有効商談数、意思決定者接触数、提案提示数 | 定義した条件を満たす商談・接点の件数 | 量ではなく質が見える設計(誰に・何を・次に何が決まったか) |
| データ品質(AIの土台) | 必須項目充足率、重複率、更新遅延 | 必須項目が埋まっている割合、重複候補件数 | AI予測の信頼性の監視、改善対象チームの特定 |
ダッシュボードは「経営向けに1枚」「現場向けに1枚」のように単純化しすぎると、結局は会議の場で追加集計が発生します。AI SFAでは、役割ごとに必要な粒度を切り替えられ、会議の問いにその場で答えられる導線が重要です。
- 経営(役員・事業責任者)向け予算に対する着地見込み、予実差の要因分解(件数・単価・時期)、主要リスクと打ち手、重点領域(業界・商材・地域)の伸び/落ちを把握できる構成が有効です。
- 営業責任者・マネージャー向けチーム別のパイプライン健全性、ボトルネック(転換率・滞留)、要支援案件のリスト、案件レビューで確認すべき論点のサマリが重要になります。
- 案件オーナー(担当者)向け次アクション、過去のやり取りの要点、提案準備のToDo、同種案件の勝ちパターンなど、「今日何をすべきか」に直結する表示が定着を促進します。
AI SFAを前提にするなら、ダッシュボードは「眺めるもの」ではなく、異常検知(遅延・停滞・急な確度低下)→要因の提示→推奨アクション→実行の記録までがひとつのループとしてつながっていることが理想です。ここまで設計できると、マネージャーは集計作業から解放され、介入の優先順位付けと育成(コーチング)に時間を使えるようになります。
以上の要件を満たすと、AI SFAは「入力された情報を眺めるSFA」から、経営判断と現場の行動を同時に前進させる営業マネジメント基盤へと変わります。
4. AI前提の顧客データ設計
AI SFAの価値は「AI機能があるか」ではなく、AIが判断できる形で顧客データが整っているかで決まります。AIは、過去の入力や活動履歴、商談結果の「パターン」から提案や予測を行いますが、データがバラバラ(表記ゆれ・重複・欠損・定義の不一致)だと、学習も推論も安定しません。
この章では、AI活用を前提にした「名寄せ」「活動履歴」「商談ステージと失注理由」の設計を、運用で崩れにくい形に落とし込みます。ツールやベンダーに依存しない考え方として押さえておくと、既存のSFAやCRMを活かしながらAI機能を効かせやすくなります。
4.1 顧客と企業の名寄せ方針
AI SFAで最初に詰まるのが名寄せです。顧客データが「同じ会社なのに別レコード」「同じ担当者なのに複数レコード」になっていると、活動履歴が分断され、AIは顧客理解や次アクション提案を誤りやすくなります。したがって、導入初期に名寄せ(同一性判定)のルールを“技術”ではなく“方針”として先に決めることが重要です。
名寄せは大きく分けて「企業(法人)」「部署(任意)」「担当者(個人)」の3つの単位で設計します。BtoBでは企業を軸に活動が積み上がるため、企業マスタの一意性が特に重要です。
名寄せ方針で決めるべき項目は、おもに次の4つです。
- 何を“同一”とみなすか(同一性の定義):企業名が同じなら同一なのか、住所や法人番号まで一致が必要なのか、など。
- どの識別子を“優先キー”にするか:法人番号、ドメイン、電話番号など、優先順位を決めます。
- 統合(マージ)時にどの値を残すか(サバイバルルール):新しい方を残す/信頼できるソースの方を残す/手入力より基幹連携を優先する、など。
- 誰が最終判断するか(責任と承認フロー):自動マージはどこまで許可するか、疑義がある場合の確認者は誰か、を決めます。
日本国内のBtoBで「企業を一意に近づける」うえで強いキーの一つが法人番号です。法人番号は制度として整備されており、社名変更や表記ゆれに影響されにくい利点があります。参照データとして、国税庁の法人番号公表サイトを確認できます。
| 識別子(候補) | 推奨対象 | 強み | 注意点(よくある落とし穴) | 運用のコツ |
|---|---|---|---|---|
| 法人番号 | 企業(法人) | 表記ゆれに強く、長期的に安定しやすい | 未取得の企業・海外法人・任意団体では使えない場合がある | 取得できる企業は優先して登録し、未取得の場合の代替ルールも用意する |
| 企業ドメイン(例:example.co.jp) | 企業(法人)、担当者 | メール連携・自動収集と相性が良い | グループ会社で共有ドメイン、代理店・外注が顧客側ドメインでない、フリーメール混在などで誤判定しうる | 「企業ドメイン=企業を一意」と決め打ちせず、補助キーとして扱う |
| 電話番号 | 企業(法人)、拠点 | 入力されやすく、重複検知の補助に使える | 代表電話の変更、部署直通、コールセンター番号の共有で揺れる | ハイフン有無などを正規化して保存し、複数番号を持てる設計にする |
| 住所(都道府県・市区町村・番地) | 企業(法人)、拠点 | 法人番号がない場合の補助キーとして有効 | 表記ゆれ(丁目/番地、全角半角、ビル名)、移転で揺れる | 郵便番号・住所の正規化(例:日本郵便の郵便番号データ活用)を前提に設計する |
| 担当者メールアドレス | 担当者(個人) | 個人の一意性に近づけやすい | 代表アドレス共有、異動・退職で無効化、個人携帯メールなどが混ざる | 「最新メールアドレス」と「過去メールアドレス(別名)」を分けて持てると引き継ぎに強い |
名寄せは精度だけでなく、説明可能性も重要です。現場が「なぜ統合されたのか」が分からないと不信感につながります。AI前提では、名寄せ結果そのものに“根拠(どのキーが一致したか)”を残す設計が有効です。例えば「法人番号一致」「ドメイン一致」「住所一致(正規化後)」のように判定根拠を保持すると、誤統合が起きたときの修正が早くなります。
また、名寄せの目的は「データをきれいにすること」ではなく、活動履歴・商談・契約・請求などの“顧客の物語”を一つに束ねることです。名寄せのルールは、営業現場の使い方(どの単位で提案し、どの単位で受注するか)に合わせて決める必要があります。
4.2 活動履歴の粒度と保存方針
AI SFAの自動提案(次アクション提案、リスク検知、提案書の下書き、要約など)は、活動履歴の質に大きく依存します。ここでいう活動履歴とは、単なる「メモ」ではなく、誰が・いつ・誰と・何を目的に・どんな結果になり・次に何をするかが追えるイベントデータです。
粒度設計のポイントは、「細かすぎて入力が続かない」か「粗すぎて学習できない」を避けることです。AI前提では、入力を増やすのではなく、メール・カレンダー・電話・Web行動などの自動収集を前提に、最小限の人手入力で意味のある構造を作ります。
活動履歴で最低限そろえるべき構造(推奨)を、イベント型として整理すると次のようになります。
| 活動タイプ | 例 | 必須フィールド(AI前提の最小セット) | あると強いフィールド(AIの精度が上がる) | 設計上の注意 |
|---|---|---|---|---|
| メール | 提案送付、日程調整、質問回答 | 送受信日時、送信者、宛先(To/Cc)、件名、紐づく企業/担当者/商談 | 本文、添付ファイル種別、スレッドID、要約、返信までの時間 | 本文を扱う場合は「保存の可否」「閲覧権限」「マスキング」設計が必要 |
| 商談(打ち合わせ) | 初回ヒアリング、提案説明、稟議前のすり合わせ | 実施日時、参加者、目的(選択式)、結果(選択式)、次アクション、紐づく商談 | 議事録、決裁者の関与有無、論点タグ(価格/機能/体制など) | 「目的」「結果」を自由記述にすると集計できないため、選択式+補足が安定 |
| 電話 | フォローコール、留守電、折り返し | 発着信日時、相手(企業/担当者)、通話結果(接続/不在など)、次アクション | 通話時間、要点メモ、録音の有無 | 「不在」も重要なシグナルになるため、結果を構造化して残す |
| タスク | 見積作成、社内確認、契約書レビュー依頼 | 期限、担当者、ステータス、紐づく商談 | 依存関係、ブロッカー理由(選択式) | タスク完了率はAIの“進捗遅延”検知に効くため、未完理由の型があると強い |
| 資料送付 | 会社案内、提案書、見積書 | 送付日時、資料種別、版(version)、紐づく商談 | 閲覧有無、反応(質問/返信)、差し替え理由 | 「どの資料をいつ出したか」は勝ちパターン抽出に直結する |
保存方針で重要なのは「後からAIに食べさせるために全部残す」ではなく、後から検証できる形で残すことです。たとえばメール本文を保存しない設計でも、件名・送受信日時・相手・スレッド単位の回数・返信速度などを構造化して残せば、商談の温度感や停滞は推定しやすくなります。
また、活動履歴には「いつの情報か」が決定的に重要です。AIによる要約や提案を実務で使える品質にするために、次のような時間情報を最低限統一します。
- タイムスタンプの基準(JSTなど)を統一する:複数ツール連携時に時差で並びが崩れると、時系列の解釈を誤ります。
- 開始/終了(所要時間)を持てる設計にする:会議や電話の長さは重要なシグナルになることがあります。
- 作成日時と更新日時を分けて保持する:後追い入力(まとめ入力)が起きても、事実の発生日を追えるようにします。
最後に、AI活用を阻害しやすいのが「活動履歴が商談に紐づいていない」状態です。企業・担当者には紐づいていても、どの商談のどの局面の活動なのかが追えないと、勝ちパターン・失注パターンの学習が難しくなります。自動収集した活動も含めて、活動→商談の紐づけを“後からでも修正できる”運用(例:一定期間は紐づけ変更可、変更履歴を保持)を前提に設計すると、定着しやすくなります。
4.3 商談ステージ定義と失注理由の設計
AI SFAの予測やアラートは、商談ステージの定義が曖昧だと機能しません。たとえば「提案中」の中に、初回提案直後も、稟議直前も、条件合意済みも混ざっていると、AIは同じラベルの中で違う状態を学習してしまいます。重要なのは、ステージ名よりもそのステージに“入った/出た”と判断できる条件(入退場条件)です。
ステージ設計は、次の3点を満たすとAIの学習・予測が安定します。
- ステージごとに「完了条件」を文章で定義する:担当者ごとの解釈差を減らします。
- ステージごとに必須項目(ゲート)を最小限だけ置く:入力を増やしすぎると更新が止まり、結果としてAIが使えません。
- ステージは“細かくしすぎない”:細分化は一見精緻ですが、運用で崩れやすく、データが薄くなります。
以下は、BtoBの一般的な流れに沿ったステージ例です。実際には商材・営業プロセスに合わせて調整しますが、AI学習の観点では「ステージ数より、定義と必須項目の一貫性」を優先します。
| ステージ例 | 完了条件(例) | その時点で必須にしたい情報(最小) | AIで効きやすい補助情報 |
|---|---|---|---|
| 初回接触 | 商談として扱うべき課題/検討が存在し、次回の会話が確定した | 顧客の課題(選択式+補足)、次回アクション日 | 検討背景、競合の有無 |
| 要件整理(ヒアリング) | 意思決定に関与する人物・要件・期限のうち、最低限が把握できた | 決裁者/推進者(分かる範囲で)、導入希望時期 | 現行の運用、制約条件(セキュリティ/契約) |
| 提案 | 提案内容が提示され、顧客が次の判断に必要な情報を受け取った | 提案日、提案パターン(選択式)、次回アクション | 提案書種別、顧客の反応(選択式) |
| 見積・条件調整 | 価格・範囲・体制などの条件が議論され、論点が整理されている | 見積金額(レンジでも可)、主要論点(選択式) | 値引き理由、契約形態 |
| 稟議・決裁 | 顧客側の意思決定プロセスに入り、判断時期の見通しがある | 決裁予定日、決裁者関与の有無 | 社内稟議の障壁(選択式) |
| 受注 / 失注 | 契約締結、または見送りが確定した | 結果日、失注理由(選択式)、競合(任意) | 再提案可能性、再接触予定日 |
失注理由は、AIの学習データとして特に価値が高い一方で、最も設計を誤りやすい項目です。自由記述だけにすると集計も学習も難しくなり、選択肢だけにすると現場が「実態と違う」と感じて入力が形骸化しやすくなります。したがって、「選択式(一次理由)+補足(任意)」を基本形にするのが現実的です。
失注理由の分類は、少なくとも次の観点を分けて設計すると、改善アクションにつながりやすく、AIも学習しやすくなります。
- 自社要因(価値・提案・体制):機能不足、提案の適合度、導入支援体制、レスポンスなど
- 顧客要因(予算・優先度・稟議):予算化できない、優先度低下、決裁者不在、時期延期など
- 競合要因:競合に決定、既存ベンダー継続、内製など
- 失注と未追客の区別:連絡不能、棚上げ、失注確定ではない停止(ステータス設計)
4.3.1 失注理由をAIに学習させるための粒度
AIにとって学習しやすい失注理由は、「多すぎず、少なすぎず、揺れない」ラベルです。粒度が荒すぎると改善の打ち手が見えず、細かすぎると入力がばらつき、学習データとして薄まります。ここでは、AI学習を前提に“ちょうどよい粒度”を作るための設計指針を示します。
推奨する失注理由ラベルの設計指針は次の通りです。
- 一次理由は「10〜20個程度の固定ラベル」を目安にする:現場が迷いにくく、集計・学習が安定します。増やす場合は、まず「補足(自由記述)」で実態を集め、後からラベルを追加する流れにします。
- 一次理由(主因)と二次理由(副因)を分けられる設計にする:実務では「価格もあるが、決裁者が動かなかった」が頻出です。主因だけでも入力可能にしつつ、余裕があれば副因も取れる構造が有効です。
- “状態”と“原因”を混ぜない:「連絡が取れない」は状態であり原因ではありません。状態(ステータス)と、原因(理由)を分けると、AIが停滞検知と失注分析を混同しにくくなります。
- 競合名は自由入力にせず、選択式+別名管理を検討する:表記ゆれ(株式会社の有無、製品名と社名の混在)が起きやすいため、可能ならマスタ化し、難しければ「競合あり/なし」だけでも構造化します。
- ラベル変更時は“旧→新の対応表”を必ず残す:年度でラベルが変わると、過去データが学習に使いにくくなります。将来のAI活用(予測精度の継続改善)を見据え、互換性を担保します。
失注理由の入力は、責任追及に見えると必ず歪みます。運用設計としては、失注理由を「改善のためのデータ」として扱い、個人評価と直結させない姿勢を明確にすることが、結果的にAIの学習データの品質を上げます。
ここまでの設計(名寄せ・活動履歴・ステージ/失注理由)が揃うと、AI SFAは「入力の肩代わり」だけでなく、「予測の根拠を説明できる」「改善の打ち手に落ちる」形で機能しやすくなります。次章以降でデータ統合や運用に進む前に、この章の設計を“変更履歴込みのルール”として文章化しておくと、運用が崩れにくくなります。
5. 顧客データ統合の進め方
AI SFAを機能させるための「統合」は、単にデータを1か所に集めることではありません。営業・マーケ・カスタマーサクセスなど、複数部門が関わる顧客接点データを「同じ顧客を同じ顧客として扱える状態」に揃え、必要な粒度で、必要なタイミングで、必要な人が使えるようにする取り組みです。
ここでは、CRM・MA・SFAの役割分担を整理し、メール・電話・Web行動データを連携し、最後に部門ごとの分断を解消して運用を回すまでの進め方を、実務の手順に落として説明します。
5.1 CRMとMAとSFAの役割整理
顧客データ統合で最初にやるべきは、ツール選定ではなく「どの業務で、誰が、どのデータを、何のために確定させるか」を決めることです。これが曖昧だと、同じ項目が複数ツールに存在し、更新責任が不明確になり、最終的にAIが参照するデータが矛盾します。
まずはCRM・MA・SFAを、用途ではなく「確定させるデータの種類」で役割分担します。
| 領域 | 主目的(何を最適化するか) | 確定させる主データ(正とする情報) | 主なアウトプット | 統合時の連携ポイント |
|---|---|---|---|---|
| SFA | 商談進捗と営業活動の再現性 | 商談、案件金額、ステージ、活動履歴、次アクション | パイプライン、予実、アクション管理 | リード/取引先/担当者のキー統一、活動ログの集約先を決める |
| CRM | 顧客関係の長期管理と接点の一元化 | 取引先(企業)、担当者(個人)、契約、問い合わせ履歴 | 顧客台帳、契約状況、サポート履歴 | 企業・個人のマスターをどこに置くか、名寄せルールの適用先を決める |
| MA | 見込み顧客育成と獲得効率 | リード(個人)、配信履歴、スコア、フォーム回答 | ナーチャリング、スコアリング、MQL抽出 | MQL/SQLの受け渡し条件、配信・反応ログをSFA/CRMへ渡す範囲を決める |
役割整理の要点は、次の3つです。
- マスター(正)となる顧客情報の置き場所をひとつに決める:企業名・住所・業種・担当者の所属など、上流の顧客情報が複数に散ると、AIの出力(要約、提案、予測)がブレます。
- 「作られるデータ」と「参照されるデータ」を分けて設計する:たとえばMAが作る行動ログはMA側で生成されますが、営業が参照する必要があるものだけをSFAに渡す、といった切り分けが重要です。
- データ項目ごとに更新責任者(一次情報の持ち主)を決める:誰でも更新できる状態は、統合後に品質が落ちやすい典型です。
次に、統合の「粒度」と「キー」を確定させます。最低限、次のキー設計を先に合意しておくと、後工程の連携が安定します。
- 企業(取引先)ID:法人番号が使える範囲は有効ですが、運用上は「自社内の一意ID」を必ず持ち、表記揺れに影響されないキーにします。
- 個人(担当者)ID:メールアドレス変更や複数アドレス保有があり得るため、メールアドレスを主キーにしない設計(補助キー扱い)が安全です。
- 商談ID:SFA上で一意にし、見積・契約・請求など周辺システムに連携する前提で採番ルールを決めます。
この役割整理の段階では「完璧な統合」を狙いすぎないことも重要です。まずは営業が毎日見るSFAに、意思決定に必要な最小限の情報が揃う状態を最優先にし、段階的に統合範囲を広げる方が定着しやすくなります。
5.2 メールと電話とWeb行動のデータ連携
AI SFAの体験価値を大きく左右するのが、接点データ(コミュニケーションログ)の統合です。商談の背景をAIが理解するためには、受注・失注の結果だけでなく、そこに至るまでの「いつ、誰が、何に反応し、どんなやり取りがあったか」が必要になります。
ただし、やみくもに全ログを取り込むと、ノイズが増え、検索性も落ちます。そこで、データソース別に「取得方法」「キー」「SFAに入れる範囲」を決めて進めます。
| データソース | 代表的な取得方法 | 紐付けキー(基本) | SFAに入れる推奨範囲 | 注意点(統合で詰まりやすい点) |
|---|---|---|---|---|
| メール | メール連携(送受信ログ同期)、BCC運用、API連携 | 担当者ID/メールアドレス(補助)/ドメイン | 件名、送受信日時、スレッド要約、添付有無などメタ情報中心 | CCに複数人が入るケース、個人アドレス(フリーメール)混在、誤紐付け |
| 電話 | CTI連携、通話ログ同期、録音データ連携 | 電話番号(補助)/担当者ID/商談ID | 発着信日時、通話時間、結果(接続/不在)、要点メモ | 代表番号・内線・転送で番号が揺れる、番号未登録が多いと紐付かない |
| Web行動 | MAタグ、Web解析ツール連携、フォーム送信の自動登録 | cookie→フォーム送信でリードに連結/メールアドレス | 重要ページ閲覧(料金、導入事例、比較、資料DL)、フォーム回答 | 匿名行動は個人に紐付けられない期間がある、同一端末の共有で混ざる |
| オンライン商談 | カレンダー連携、会議ログ連携、議事録生成ツール連携 | 予定(イベント)ID/参加者(担当者)ID | 実施日時、参加者、議題、決定事項、次アクション | 招待先の表記揺れ、外部ゲストのメール変更、会議名だけでは判別不能 |
連携設計は、次の順序で行うと破綻しにくくなります。
- 「SFAに保存する接点ログの目的」を決める:営業が案件を前に進めるために必要なログか、監査・証跡目的か、ナレッジ目的かで、保存すべき範囲と保持期間が変わります。
- イベント(活動)を共通フォーマットに変換する:メール、電話、Web行動をそのままの形式で入れるのではなく、「活動種別」「日時」「主体」「相手先」「要点」「次アクション」「関連商談」といった共通項目に寄せます。これにより、AIが横断的に要約しやすくなります。
- 紐付けルールを明文化する:例として「取引先ドメイン一致は企業候補として紐付けるが、担当者は人手で確定する」「電話番号一致は候補に留め、確定は担当者が行う」など、誤紐付けを前提にした設計が現実的です。
- 同期頻度と遅延許容を決める:リアルタイムが必要なもの(フォーム送信→即通知)と、日次バッチで良いもの(閲覧ログの集計)を分け、API制限や運用負荷を抑えます。
この章の観点で特に重要なのは、「連携できるか」ではなく、連携した結果、誰が何を判断できるようになるかです。たとえばWeb行動ログは量が膨大になりやすいため、SFAには「重要行動のみ(例:料金ページ閲覧、比較ページ閲覧、資料DL、導入事例閲覧)」をイベント化して入れ、詳細ログはMA側に残す、といった棲み分けが有効です。
5.3 部門ごとの顧客データ分断をなくす方法
顧客データ統合が止まりやすい最大の要因は、技術ではなく組織です。営業、マーケティング、インサイドセールス、カスタマーサクセス、サポート、請求などで「顧客」の見方が違うと、同じ顧客に複数のレコードが作られ、正しい分析もAI活用も難しくなります。
分断を解消するためには、全社統一を一気に目指すのではなく、「衝突しやすい論点」を先に決め、運用で守れる範囲に落とすことが現実的です。
まず、分断のパターンを洗い出し、対策を対応表にします。
| よくある分断 | 現場で起きる問題 | 統合の基本方針 | 運用で決めること(例) |
|---|---|---|---|
| 企業名の表記揺れ(株式会社/(株)、全角半角、部署名混在) | 名寄せできない、重複企業が増える | 企業マスターの正規化 | 登録ルール、候補提示と承認フロー、既存データの一括クレンジング手順 |
| 個人(担当者)の重複(異動・転職・複数メール) | 同一人物の履歴が分散し、引き継ぎが弱くなる | 担当者IDの一意化と履歴統合 | メールアドレス変更時の統合手順、退職者の扱い、名刺情報の取り込み基準 |
| 部門ごとに「顧客ステータス」が違う | 営業とCSで見ているステージが噛み合わない | 顧客ライフサイクルの共通化 | マーケ(リード)→営業(商談)→契約→利用継続の共通状態と遷移条件 |
| 同じ項目が複数システムに存在(住所、電話番号、担当者など) | どれが最新かわからない、更新されない | 更新元(System of Record)を決める | 項目ごとの更新責任、同期方向(片方向/双方向)、例外時の手修正ルール |
| 「商談」の単位が違う(案件/見積/プロジェクト/部門別) | 予測が合わない、過去比較ができない | 商談の粒度を統一 | 分割・統合のルール、親子商談の扱い、アップセル/更新の計上単位 |
次に、統合を前に進めるための進め方(合意形成と実装の段取り)を明確にします。ポイントは、会議体ではなく「決める順番」です。
- 共通語彙(用語)を決める:取引先・顧客・担当者・リード・商談・契約など、部門で意味がズレやすい語を揃えます。ここが揃うと、データ定義の議論が前に進みます。
- 顧客ライフサイクルを1本の線で定義する:マーケ起点でも営業起点でも、最終的に「同じ顧客の時間軸」に乗るように、状態と遷移条件を決めます。
- マスター項目の「更新元」と「配布先」を固定する:更新元が複数あると、統合後の整合性が保てません。項目ごとに「誰が、どこで、いつ更新するか」を決めます。
- 統合のスコープを段階化する:最初から全部門・全データを統合しません。例として、第一段階は「企業・担当者の名寄せ+商談と主要活動ログ」、第二段階は「MA行動ログの要点同期」、第三段階で「サポート・請求まで含めた拡張」という形で増やします。
統合の実装方式は、目的と体制に合わせて選びます。ここで重要なのは、方式の流行ではなく、データ品質を維持できる運用に落ちるかです。
| 方式 | 概要 | 向いているケース | つまずきやすい点 |
|---|---|---|---|
| API連携(双方向/片方向) | システム間でデータを自動同期する | リアルタイム性が必要、標準連携がある | 例外処理(重複、削除、権限)を詰めないと不整合が増える |
| バッチ連携(CSV/ETL) | 定期的に抽出・変換・投入する | 日次で十分、既存システムが古い | 「最新版」がどれか分からなくなると破綻しやすい |
| iPaaS(連携基盤) | 連携フローを集中管理しやすい | 連携先が多い、運用変更が多い | ブラックボックス化すると保守不能になるため、仕様のドキュメント化が必須 |
| 統合データ基盤(DWH/データレイク) | 分析・AI用に横断データを集約する | BI分析や高度な予測も見据える | 現場運用と分離しすぎると、日々の業務改善に繋がりにくい |
最後に、部門横断の分断を「なくす」ための実務上のコツを整理します。
- 統合の成果指標を「入力率」ではなく「探索時間の短縮」に置く:部門ごとに協力を得るには、「自部門の得」になる指標が必要です。たとえば「顧客の最新状況が探せない」を解消するのが最も合意を作りやすいテーマです。
- データ修正を“依頼”ではなく“申請”にする:誰でも書き換えられるとマスターが壊れます。一方で、修正できないと放置されます。現場が困る頻出項目(企業名、部署名、担当者異動など)は、申請→承認→反映の導線を短く設計します。
- 重複・不備を検知する仕組みを先に入れる:統合は「一度きれいにする」では終わりません。重複候補の自動検知、必須項目の欠落アラートなど、品質が落ちる前に気づける形にします。
- 統合対象は“使うデータ”から始める:使われないデータを統合しても、メンテナンスされず品質が落ちます。営業が意思決定に使う項目(案件金額、ステージ、次アクション、キーパーソン、競合状況など)に直結するデータから統合します。
この章で扱った「統合の進め方」を一言でまとめると、顧客データ統合は技術導入ではなく、“正しい情報が自然に集まる流れ”を部門横断で合意し、維持する設計です。ここまで整うと、AI SFAの提案・要約・予測は、現場の体感として「当たる」方向に寄っていきます。
6. AI SFAで起きやすい失敗と対策
AI SFAは、入力負荷を減らしたり、商談の優先順位や次アクションを提案したりと、営業組織の生産性を押し上げる可能性があります。一方で、導入後に「結局使われない」「AIの提案が当たらない」「データが荒れて余計に見づらい」といった失敗も起きやすい領域です。
ここでは、現場・マネージャー・経営のどの目線でもつまずきやすい典型パターンを、原因と対策に分けて整理します。ポイントは、AIの精度以前に、信頼・運用・データ品質の3点が揃わないと成果が出ないことです。
6.1 AI提案が信用されない原因
AI SFAが提案する「次に取るべきアクション」「優先フォローすべき顧客」「受注確度」「売上予測」などが信用されないと、現場はAIを無視し、結局は勘と経験に戻ってしまいます。多くのケースで、問題はAIの存在そのものではなく、提案の根拠が見えない設計、あるいは学習・推論に使われるデータが現場の実態とズレていることにあります。
| 起きている症状 | 現場が不信に感じるポイント | よくある根本原因 | 優先すべき対策 | 確認すべき指標 |
|---|---|---|---|---|
| AIの確度・スコアが「体感」と合わない | 「この案件が高スコアの理由が分からない」 | 活動履歴の未入力・偏り、商談ステージが形骸化、過去データに偏った学習 | 根拠(寄与要因)を画面で見せる、スコア算出の前提を統一する | スコア上位案件の受注率、誤検知率、未入力率 |
| AIの提案が抽象的で行動に落ちない | 「結局何をすればいいの?」 | 営業プロセスと提案ロジックが未接続、提案の粒度が合っていない | 「誰が・いつまでに・何を・どのチャネルで」まで落とす | 提案からタスク化された割合、タスク完了率 |
| 提案が一部の営業だけ当たり、他は当たらない | 「部署・商材で使えない」 | 商材別の勝ちパターン差、顧客セグメント差、データ量の不足 | 適用範囲を限定して成功事例を作り、段階的に広げる | 部門別の精度、利用率、受注率の改善幅 |
| AIの提案が「ノイズ」に見え、通知が無視される | 「通知が多すぎる」 | しきい値設計が不適切、通知設計が役割別になっていない | 通知の優先度設計、役割別(営業・マネージャー)に出し分け | 通知の開封率、通知起点の行動率、解除率 |
6.1.1 信頼を作るための「根拠表示」設計
AI提案が受け入れられるかどうかは、精度だけでなく「納得できるか」で決まります。現場の納得を作るために、提案の横に根拠を添える設計が重要です。
- 提案に紐づく事実データ(活動・反応・商談情報)をワンクリックで確認できるようにします(例:直近のメール返信、Webフォーム送信、商談議事録の要点、決裁者との接点など)。
- 「このアクションを推奨する理由」を、営業の言葉で説明できる形にします(例:競合が出ている、提案先部署が固まっていない、稟議期限が近い)。
- 確信度が低い提案は、あえて「参考」扱いとして区別します。不確実な提案まで断定すると、外れたときに信用を大きく失うためです。
- 提案の対象者(営業担当者・マネージャー・インサイドセールス)によって、根拠の見せ方を変えます。担当者には行動の根拠、マネージャーにはリスク要因の根拠が有効です。
6.1.2 現場フィードバックで「外れ方」を学び、改善ループを回す
AIが外れること自体は避けられません。問題は、外れた原因が見えず改善されないことです。AI SFAの運用では、人が最終判断をしつつ、外れた理由をデータとして回収する仕組みが重要です。
- AI提案に対して、営業が「採用した/見送った」をワンタップで残せるようにし、見送った場合は簡単な理由を選択式で残します(自由記述だけにしない)。
- 週次・月次で「当たった提案/外れた提案」を棚卸しし、外れた原因がデータ欠損なのかプロセスの例外なのかモデルの前提のズレなのかを切り分けます。
- 「AIに従う/従わない」の対立にしないために、会議の場ではAI提案を“参考情報のひとつ”として扱い、判断根拠を言語化する文化を作ります。
6.2 入力ルールが増えて逆に使われない原因
AI活用を進めるほど、「学習させるために入力が必要」という発想になりがちです。しかし入力項目や必須ルールを増やすと、現場の負担が増え、入力が遅れ、結果としてデータが歪み、AIの精度も落ちます。これは典型的な悪循環です。
重要なのは、入力を増やしてAI精度を上げるのではなく、入力を減らしてデータの自然発生量を増やす設計に切り替えることです。
| 失敗パターン | 現場で起きること | 見落としがちな原因 | 対策(設計・運用) |
|---|---|---|---|
| 必須項目が多く、登録が進まない | 商談登録が後回しになり、記憶頼りでまとめ入力になる | マネジメントの「欲しい項目」をそのまま必須化している | 必須は最小限に固定し、それ以外は任意・自動収集・後追いで補完 |
| ステージ更新や確度入力が形骸化する | 会議直前に辻褄合わせの更新が行われる | ステージ定義が曖昧、更新するメリットが現場にない | ステージ遷移条件を明確化し、更新すると提案・資料生成などの恩恵が出る設計にする |
| 同じ内容を複数システムに二重入力する | 「SFAにも日報にも」など、入力が分裂する | CRM・MA・SFA・グループウェアの役割が未整理 | 入力の正本を1つに決め、他は連携で持つ |
| 入力がPC前提で、外出先で更新されない | 活動履歴が溜まり、情報鮮度が落ちる | モバイル導線・音声入力・簡易入力が弱い | モバイル最適化、テンプレ化、会議後の1分入力で済むUIに寄せる |
6.2.1 最低限の必須項目を決める基準
必須項目は増やすほど管理側は安心しますが、現場負担が跳ね上がります。必須化の基準は「入力しないと業務が回らない」ではなく、入力されないとAI提案と予測が破綻する項目に限定することです。
- 重複しやすい“名寄せのキー”になる情報(例:会社名、部署、担当者名、メールアドレス、電話番号のうち運用に合うもの)
- 案件の前進を判定できる最低限の事実(例:次回アクション日、意思決定者の有無、提案中の商品・サービスカテゴリなど)
- 予測に直結する数値(例:金額、見込み時期)
逆に「入力が重い割に使われない項目」(例:長文の所感、細かすぎるカテゴリ、毎回変わる可能性が低い属性)は、任意・自動収集・テンプレ化・別画面化などで負担を下げるべきです。
6.2.2 自動入力が難しい領域の「最小負担」設計
すべてを自動化できない場合でも、入力を“短く・迷わせない”設計にすることで、定着率は大きく変わります。
- 自由記述を減らし、選択式+必要なら補足だけ自由記述にします(例:失注理由、停滞理由、競合の有無)。
- 入力タイミングを固定します(例:商談終了後24時間以内、週次会議の前日まで)。入力を「いつでもOK」にすると、結局いつまでも入力されません。
- 入力導線は画面遷移を減らし、同一画面で完結させます。特に活動履歴は、入力コストが小さくなるほど“情報の量と鮮度”が上がります。
- 入力のメリットを即時に返します。たとえば、活動履歴を入れたら議事録の要約、次の質問案、提案書のたたき台が出るなど、現場が「入れると楽になる」を体感できる流れが重要です。
6.3 データ品質が落ちる運用の落とし穴
AI SFAは、データが増えるほど価値が出ますが、同時に「増えるほど荒れる」リスクも抱えています。典型的には、重複、表記ゆれ、古い情報の放置、会議前の辻褄合わせ更新、担当変更の未反映などが積み重なり、AI提案の精度と現場の信頼を同時に落としていきます。
対策の要点は、データ品質を“個人の頑張り”に依存させず、仕組みと役割で担保することです。
| データ品質の落とし穴 | 起きやすい状況 | AI SFAへの悪影響 | 対策(運用・機能) |
|---|---|---|---|
| 顧客・担当者の重複登録(名寄せ不全) | 名刺交換後の手入力、部署違いで別登録、表記ゆれ | 履歴が分散し、スコア・予測が不安定になる | 重複検知ルールを用意し、統合の責任者を決める |
| 活動履歴が抜ける・遅れる | 外出が多い、入力が面倒、会議直前にまとめて入力 | 提案がズレる、タイムリーなリスク検知ができない | カレンダー・メール・通話履歴などから自動収集し、未記録をアラート |
| 商談ステージが実態と一致しない | 定義が曖昧、会議運用が先にありSFAが後追い | パイプラインが信用されず、予測精度が落ちる | ステージ遷移条件を明文化し、会議の型と揃える |
| 失注理由がバラバラ(自由記述のみ) | 入力者により粒度が違う、言い回しが揺れる | 勝ちパターン・改善点が学習されない | 選択式の理由カテゴリ+補足、定期的なカテゴリ棚卸し |
| 更新されない休眠案件が溜まる | 担当者の異動、優先度低下、見込み薄で放置 | 予測が膨らみ、リソース配分が誤る | 一定期間アクティビティがない商談は棚卸し対象にする |
6.3.1 品質を保つための「役割」と「点検」の設計
データ品質は、ルールだけでは守られません。責任範囲と点検頻度を決め、日常業務に埋め込む必要があります。
- データの責任者(データオーナー/データ管理担当)を明確にすることが第一歩です。たとえば、顧客マスタの統合、項目定義の変更、重複の解消などは、営業個人の善意では回りません。
- 点検は「気づいたら直す」ではなく定例化します(例:週次で停滞商談、月次で重複・未入力・異常値)。
- 入力ミスを“叱る”運用にしないことも重要です。罰則型にすると、現場は本音(失注理由や停滞理由)を入力しなくなり、AIの学習に必要な情報ほど失われます。
6.3.2 品質指標を「見える化」して、AI精度と紐づける
AI SFAの評価が「AIが当たる/当たらない」だけになると、改善が進みません。データ品質を数値化し、AIの精度や現場の利用率と関連づけて追うことで、改善の打ち手が明確になります。
| 品質指標 | 意味 | 例 | 改善アプローチ |
|---|---|---|---|
| 必須項目の充足率 | 最低限の判断材料が揃っているか | 金額・時期・次回アクション日の未入力率 | 必須の再設計、未入力の自動検知、入力導線の短縮 |
| 活動履歴の鮮度 | 情報が“今の状況”を反映しているか | 最終活動から14日以上空いている商談の割合 | 自動収集、停滞アラート、棚卸しの定例化 |
| 重複率(名寄せの健全性) | 同一顧客が分裂していないか | 同一ドメインの担当者が複数アカウントに分散 | 重複検知、統合フロー、表記ルールの統一 |
| ステージ整合率 | ステージが実態に合っているか | ステージは進んでいるのに次回予定がない | 遷移条件の明確化、会議運用の見直し、監査ルール |
| 失注理由の分類率 | 学習・改善に使える形で残っているか | 「その他」比率が高い | カテゴリ見直し、選択肢の改善、入力の負担軽減 |
AI SFAの失敗は、ツール選定よりも、信頼を作る設計・入力負担を増やさない運用・品質を落とさない仕組みでほとんどが防げます。AIの提案が使われ、データが回り、精度が上がる好循環を作るために、この章で挙げた失敗パターンを事前に潰しておくことが重要です。
7. ガバナンスとセキュリティ
AI SFAは、営業メンバーの活動(メール・電話・Web会議・商談メモ)を横断して集約し、要約・提案・予測などの支援を行います。そのため、従来のSFA以上に「誰が、どの情報に、どこまでアクセスできるか」「個人情報や機密情報をどう扱うか」「外部AI(生成AIや解析基盤)にデータを渡す場合の統制」を明確にしないと、現場の不安や利用停止、監査指摘、情報漏えいリスクに直結します。
AIの精度を上げるためにデータを集めるほど、統制が弱い組織はリスクが増えます。だからこそ、AI SFAは「ガバナンス前提」で設計・運用することが最短ルートです。
7.1 権限設計と閲覧範囲の最適化
AI SFAの権限設計では、単に「営業は見られる/見られない」ではなく、顧客・商談・活動履歴・添付ファイル・通話録音・議事録・生成された要約や提案文など、情報の種類ごとに閲覧範囲を分ける必要があります。特に、AIが自動収集したデータは本人が入力した意識が薄く、意図せず機微な情報が混入しやすいため、アクセス制御を細かくするほど事故を防げます。
7.1.1 基本方針(最小権限・職務分掌・例外の管理)
運用に耐える権限設計は、次の3つを原則にすると破綻しにくくなります。
- 最小権限(Least Privilege):業務に必要な範囲に限定して閲覧・編集を許可する。
- 職務分掌:管理者権限を1人に集中させず、設定変更と監査確認の責任を分ける。
- 例外の管理:個別例外(役員閲覧、兼務、プロジェクト)の付与・期限・承認履歴を残す。
7.1.2 ロール(役割)設計のひな型
組織の規模や商材により異なりますが、AI SFAでは「営業担当」「営業マネージャー」「営業企画(RevOps)」「情シス/セキュリティ」「役員」「外部パートナー(代理店・業務委託)」のように、責務単位でロールを切ると運用が安定します。以下は、検討のたたき台です。
| ロール | 主な閲覧範囲 | 主な編集権限 | 注意点(AI SFA特有) |
|---|---|---|---|
| 営業担当 | 自分の担当顧客・商談・活動履歴 | 自分の案件更新、メモ追記、次アクション | AI要約の共有先を誤ると情報が広がるため、共有操作の制限と確認UIが重要。 |
| 営業マネージャー | 配下メンバーの顧客・商談・活動履歴、チームKPI | 商談ステージの承認、失注理由の確定、フォーキャスト入力 | マネージャーが「全社の通話内容」まで見える設計は心理的抵抗を生むため、閲覧粒度を定義する。 |
| 営業企画(RevOps) | 全社の商談データ(原則は匿名化・集計中心) | 項目定義、レポート、ダッシュボード、入力ルール | 生ログ(通話録音・全文議事録)へのアクセスは限定し、統計・傾向分析に寄せる。 |
| 情シス/セキュリティ | 監査ログ、権限設定、連携設定、利用状況 | SSO/MFA設定、連携の許可、データ持ち出し制御 | 内容そのものではなく、設定とログ中心に権限を付与して職務分掌を担保する。 |
| 役員 | 全社の集計指標、重要案件(限定) | 原則なし(閲覧中心) | 「何でも見られる」権限は炎上リスクが高い。重要顧客・重要案件のみ閲覧可能にする設計が現実的。 |
| 外部パートナー(代理店・業務委託) | 自社に紐づく顧客・商談のうち必要最小限 | 活動報告、案件更新(制限付き) | 自社の他顧客が検索・推薦で見えてしまう事故を防ぐため、検索範囲・推薦対象の制御が必須。 |
7.1.3 監査ログと変更管理(証跡を残す)
権限設計は「作って終わり」ではなく、運用中の変更が最も危険です。AI SFAは連携や自動収集の設定変更で、収集範囲が一気に広がることがあります。次のログが追えるかを、導入時点で確認しておくと、監査対応と事故原因の特定が容易になります。
- 権限ロールの作成・変更・削除の履歴(誰が、いつ、何を変えたか)
- データエクスポート(CSV出力等)・大量閲覧の履歴
- 外部連携(メール、カレンダー、通話、Web会議、MA等)の追加・変更履歴
- AI機能の設定変更(要約保存、学習利用の有無、共有範囲)
7.2 個人情報保護法に配慮した運用
AI SFAでは、名刺情報、メール署名、通話記録、商談メモに含まれる担当者名・連絡先・所属など、個人情報を取り扱う場面が増えます。さらに、会話の録音・文字起こし・要約といったデータは、本人の認識以上に情報量が多く、取り扱いを誤ると影響が大きくなります。個人情報保護法に基づく運用は、社内規程だけでなく、実際の業務フローに落とし込むことが重要です。
法令の一次情報は、個人情報保護委員会の公表情報を参照しながら、自社の「利用目的」「取得方法」「保管期間」「第三者提供」「委託先管理」を整理してください。
個人情報保護委員会の公開情報を踏まえ、社内の運用ルールとSFA設定を一致させることが、現場の混乱を防ぎます。
7.2.1 AI SFAで扱いが増える個人情報と、運用上の論点
AI SFAで特に論点になりやすいデータを、運用観点で整理します。
| データ例 | AI SFAで起こりやすいこと | 運用上の主な論点 | 推奨対応(例) |
|---|---|---|---|
| 名刺情報(氏名・会社・メール・電話) | 自動取り込みや重複統合で、誤名寄せが起きる | 利用目的の明確化、誤登録訂正の手順 | 取込元の記録、訂正フロー、統合ルールと例外処理を定義する |
| メール本文・署名 | 自動収集で、機密や私用連絡が混入する | 取得範囲の最小化と、閲覧範囲の制御が不可欠。 | 収集対象のフォルダ・ドメイン制限、検索範囲制御、アクセスログ監視 |
| 通話録音・文字起こし | 本人が想定しない情報(個人の事情等)が残る | 取得時の通知・同意、保管期間、アクセス制限 | 録音の告知、保管期限の設定、閲覧者の限定、機微情報の削除手順 |
| 商談メモ(議事録・課題・予算) | 生成AI要約で、社内外共有が容易になる | 社外共有のルール、誤生成の訂正責任 | 共有テンプレート、承認フロー、要約の校正・確定ステータスを導入する |
7.2.2 「利用目的」「保管期間」「削除」の3点を先に決める
AI SFA導入で最も揉めやすいのが、「どこまで集めるか」よりも「集めた後にどうするか」です。以下の3点を、規程と設定の両面で決めると運用が安定します。
7.2.3 委託先管理(クラウド運用の現実解)
AI SFAはクラウド提供が主流であり、運用保守やデータ保管を外部事業者に委託する形になりがちです。この場合、契約と運用の両面で「委託先の管理」を行い、社内の安全管理措置と整合させることが重要です。
- 委託先の安全管理措置(アクセス制御、暗号化、ログ、脆弱性対応)の確認
- 再委託の有無と範囲(サブプロセッサ)の把握
- 事故発生時の連絡体制(通知期限、一次報告の内容、共同調査の可否)
- 契約終了時のデータ返却・消去の方法(証明書の発行可否を含む)
7.3 外部AI利用時のデータ持ち出し対策
AI SFAの「AI」は、SFA製品に内蔵された機能だけでなく、外部の生成AI(大規模言語モデル)や音声認識、要約API、社内データ検索(RAG)基盤などを組み合わせて実現されることがあります。外部AIを使うほど便利になる一方で、入力データが組織外へ送信される可能性が高まり、情報漏えい・目的外利用・規程違反のリスクが増えます。
外部AI対策の本質は、「送らない」「送るなら最小限」「送った後を追える」の3点を、技術と運用で同時に満たすことです。
7.3.1 ベンダー審査で確認すべきチェック項目
外部AIや外部APIを利用する場合、導入前に最低限の審査項目を揃えると、後から止めるコストを減らせます。セキュリティ監査部門がある企業では、情シスと営業企画が共同でチェックシート化しておくとスムーズです。
| 観点 | 確認したい内容 | なぜ重要か |
|---|---|---|
| データの利用 | 入力データが学習・再利用されるか、されないか(選択肢の有無) | 営業の機密情報や個人情報が、意図せず二次利用されるリスクを下げるため |
| 保管と削除 | 送信データの保管期間、ログの保存範囲、削除要求への対応 | 監査とインシデント対応で「何が残っているか」が不可欠なため |
| アクセス制御 | 管理画面の権限分離、SSO/MFA対応、監査ログ | 設定ミス・不正アクセスによる漏えいを予防するため |
| インシデント対応 | 事故時の通知、連絡窓口、共同調査、再発防止のプロセス | AIは原因特定が難しいため、事前に対応責任を明確化しておく必要があるため |
| 第三者評価 | 外部監査報告書やセキュリティに関する公開情報の有無 | ブラックボックス化を避け、比較可能な材料を確保するため |
7.3.2 入力データの最小化(プロンプトに「顧客情報」を入れない設計)
外部AI対策で最も効果が高いのは、そもそも送信するデータを減らすことです。生成AIに投入する文章(プロンプト)に、個人名、メールアドレス、携帯番号、契約条件、未公開の価格表などが入る設計になっていると、運用で抑えるのが難しくなります。
- テンプレート化:要約や提案文の生成依頼はテンプレート化し、原文貼り付けを禁止または制限する。
- マスキング:個人名や連絡先などを自動置換してから外部AIへ送信する仕組みを検討する。
- 分割:全文を送らず、論点(課題・要望・懸念)など必要部分だけを抽出して送る。
7.3.3 技術的対策(経路・保管・操作のコントロール)
運用ルールだけでは例外が必ず起きるため、技術的対策で「できない状態」を作ることが重要です。実装可否は製品・構成で変わるため、SFA側とネットワーク側の両面で検討します。
- SSO/MFAの強制、退職者アカウントの即時無効化
- 端末制御(社給端末のみ許可、MDMでコピー&ペーストやスクリーンショットを制御できる範囲の検討)
- データエクスポート制限(CSV出力、APIトークン発行、外部連携追加の権限制御)
- 監査ログの集中管理(誰が、何を、どれくらい外部へ送ったかの追跡)
対策の優先順位付けに迷う場合は、国内の代表的なセキュリティ啓発情報を参考にしつつ、自社の業務実態(営業が扱う情報の機密度、外部共有の頻度)に合わせて現実的に設計します。
IPA(情報処理推進機構)が公開する情報セキュリティ対策の考え方も、社内教育の根拠として使いやすい一次情報です。
7.3.4 運用対策(ルールを増やすのではなく、違反しにくい導線を作る)
「外部AIに入力してはいけない情報」を文章で並べても、現場は忙しく、例外対応が積み重なって形骸化します。AI SFAの運用対策は、禁止事項の追加よりも、正しい使い方の導線設計が効果的です。
- 営業が使う画面内に、入力可否のガイド(例:個人情報や契約条件は入力しない)を表示する。
- 生成結果の利用ルールを明確化する(外部送信前提の文面・内部限定の文面など、用途別テンプレート)。
- 例外申請の窓口を作り、例外が常態化したら設計を見直す(ルールで抑えるのではなく仕組みで解決)。
7.3.5 インシデント対応(起きる前に決めておく)
AI SFAでは、「誤共有」「誤名寄せ」「外部AIへの誤送信」など、人の操作ミスに起因する事故が現実的に起こり得ます。発生時に慌てないために、最小限でも以下を事前定義しておくことが重要です。
- 初動フロー(連絡先、一次切り分け、該当データの特定、アクセス遮断)
- 影響範囲の調査方法(監査ログ、共有履歴、連携履歴)
- 社内外への報告方針(取引先・委託先・経営へのエスカレーション)
- 再発防止(権限設計、テンプレート、UI、教育の見直し)
AI SFAのセキュリティは「事故ゼロ」を宣言するものではなく、事故が起きても被害を最小化し、原因を特定できる状態を作ることが目的です。
8. 定着のための運用設計
AI SFAは「導入」よりも「定着」が成果を分けます。機能が優れていても、現場が日々の業務で使い続けなければ、データは育たず、AIの提案精度も上がりません。定着の運用設計では、入力させる仕組みではなく、使うほど得をする体験を先に作り、会議と責任分担で“使わざるを得ない流れ”を作ることが重要です。
8.1 入力の代わりに成果が出る体験を先に作る
営業メンバーがSFAを避ける最大の理由は「入力が増えるのに、自分の成果が上がる実感がない」ことです。AI SFAの定着では、まず現場の時間が本当に減る・勝率が上がるを小さくても確実に体験させ、その後に入力やルールを段階的に整えます。
8.1.1 最初の2週間で作る「使う理由」
初期フェーズでは、完璧なデータ整備よりも「明日から助かる」を優先します。たとえば次のような、現場がすぐに価値を感じるユースケースを先に実装・周知します。
- 商談準備の要約:過去のメール・議事メモ・活動履歴をAIが整理し、次回アジェンダ案を出す
- 提案骨子のたたき台:商談の目的・課題・検討状況から、提案構成を自動生成する
- 次アクションの抜け漏れ防止:期日・担当・優先度を自動でタスク化し、通知で追う
- 引き継ぎの即戦力化:担当交代時に「概要・論点・懸念・決裁者・競合」を自動サマリー化する
この段階で大切なのは、AIの出力を「正解」にしないことです。AIの提案はあくまで補助として扱い、人が最終判断する前提の運用にすることで、現場の心理的ハードルを下げられます。
8.1.2 入力項目は「増やさない」ではなく「減らす」から始める
定着しない運用の典型は、導入時に入力項目とルールを一気に増やしてしまうことです。まずは現状の運用から、入力負荷の高い項目を棚卸しし、削減・自動化・選択式化を優先します。
| 論点 | 悪い設計(定着しない) | 良い設計(定着する) |
|---|---|---|
| 入力の目的 | 「管理のために必要」 | 「本人の成果に直結する」(準備時間削減・漏れ防止・引き継ぎ短縮) |
| 入力のタイミング | 一日の終わりにまとめて入力 | 会議・電話・訪問の直後に最小限(音声メモ、テンプレ、ワンクリック) |
| 入力形式 | 自由記述が多い | 選択式+短文メモ(AIで要約・整形) |
| 入力項目の数 | 理想を詰め込み過ぎる | 「必須は3〜5個」から開始し、段階的に追加 |
| 品質担保 | 注意喚起だけで改善を期待 | 未更新の自動リマインド、差戻しの基準、更新しやすいUIで担保 |
8.1.3 「AIを使う導線」を業務フローに埋め込む
AI機能は「使いたい人が使う」状態だと定着しません。日常業務の導線にAIを組み込み、自然に使われる状態を作ります。たとえば、予定作成(GoogleカレンダーやMicrosoft Outlook)→商談ページ→事前要約→議事メモ→次アクション、という流れを一連にし、AIが“ページを開いた瞬間に役に立つ”配置にします。
8.2 営業会議の型をAI SFAに合わせて変える
ツールを現場に合わせすぎると、結局「いつものExcel」「口頭報告」に戻ります。定着の要は会議です。営業会議の型をAI SFA前提に変え、SFAに書いてあること以外は会議で扱わないくらいのルールに寄せると、更新の動機が生まれます。
8.2.1 会議アジェンダを「SFAの画面起点」に統一する
会議では、議題の入口をSFAのダッシュボード・案件一覧・アラートに統一します。口頭や個別資料の持ち込みが常態化すると、データ更新のインセンティブが消えます。次のように「SFAの情報が最新であること」を前提条件にすると、自然に運用が回ります。
- 週次:パイプライン(ステージ別・金額・確度・次アクション期日)の確認はSFA画面のみで実施
- 重点案件:AIの要約(前回論点・ネクストステップ・懸念)を読み上げ、追加の事実だけを追記
- 停滞案件:一定日数更新がない案件は自動抽出し、原因(次アクション未設定、決裁者未接触など)をその場で修正
8.2.2 マネージャーの仕事を「追い込み」から「コーチング」に変える
AI SFAが活きる会議は、詰問型の報告会ではなく、行動が変わるコーチング型です。マネージャーは「なぜ数字が悪いのか」だけでなく、SFAの情報から「次に何を変えるか」を扱います。
そのために、会議の問いを統一します。たとえば以下のように、SFAの項目と連動した問いにすると、情報が揃いやすくAIの分析も効きます。
| 会議での問い | SFAで参照する情報 | 会議のアウトプット |
|---|---|---|
| 次回までの勝ち筋は何か | 顧客課題、価値仮説、競合状況 | 勝ち筋の仮説を1つに絞り、検証行動をタスク化 |
| 決裁が進まない要因は何か | 決裁者/関与者、意思決定プロセス、停滞理由 | 誰に何を確認するかを次アクションに落とす |
| 受注確度はなぜその数値か | ステージ定義、直近活動、合意事項 | 確度の根拠を短文で追記し、更新基準を統一 |
| 失注リスクは何か | 懸念点、競合、価格条件、失注理由候補 | リスクと対策を1セットで記録(AIの学習材料になる) |
8.2.3 会議の前後で「更新する時間」を確保する
定着しない組織では、会議で指摘だけして更新する時間がありません。会議の前後に10〜15分でもよいので、SFAを更新する時間をスケジュールに組み込みます。特に次のような運用が効果的です。
- 会議の冒頭で「未更新件数」「次アクション期限超過件数」を確認し、その場で修正する
- 会議の最後に、決まったことをSFAのタスク・次アクションに落とすところまで実施する
- 更新が難しいメンバーには、テンプレ(選択式)と音声メモなど、更新手段を複線化する
8.3 データの更新責任を明確にする
AI SFAの精度はデータ品質に依存します。しかし現場に「ちゃんと入力して」と言うだけでは改善しません。定着の運用設計では、誰が・いつ・どの項目を・どの品質で更新するかを役割として定義し、評価・会議・業務フローに組み込みます。
8.3.1 更新責任の設計(RACIの考え方)
更新責任が曖昧だと、データは「たぶん誰かが入れる」状態になり、最新性が崩れます。営業担当だけに押し付けるのではなく、営業マネージャー、営業企画(Sales Ops)、マーケティング、情報システムなどの役割を整理します。
| データ/運用項目 | 営業担当 | 営業マネージャー | 営業企画(Sales Ops) | マーケティング | 情報システム/セキュリティ |
|---|---|---|---|---|---|
| 商談の次アクション・期日 | 主担当(更新) | 確認(会議でレビュー) | 運用設計(テンプレ整備) | – | – |
| 商談ステージ・確度の更新 | 更新(基準に従う) | 承認/レビュー | 基準の策定・教育 | – | – |
| 失注理由の記録(選択式+補足) | 更新(事実を記録) | レビュー(粒度の確認) | 分類のメンテナンス | 示唆の反映(施策改善) | – |
| 顧客/企業の名寄せ・重複修正 | 発見時に報告 | 重要顧客の整合性確認 | 運用と修正の窓口 | リード/アカウント整合 | 連携設定の管理 |
| 権限・閲覧範囲の運用 | – | – | 申請フロー運用 | – | 設計・監査 |
8.3.2 「更新基準」を文章化し、例で揃える
同じ項目でも、人によって解釈が違うとデータは崩れます。たとえば「商談化」「提案」「見積」「稟議」などは会社ごとに意味が異なるため、運用ルールは必ず文章で定義し、OK例/NG例をセットにします。
- ステージ更新の条件:何が確認できたら次に進めるか(事実ベース)
- 確度の付け方:主観ではなく根拠(決裁者合意、予算確保、競合優位など)
- 失注理由の粒度:選択肢+補足の最小要件(AI分析に耐える形)
- 次アクションの書き方:「誰が・いつまでに・何を・なぜ」を短文で統一
この「基準」は作って終わりではなく、会議で繰り返し参照されることで定着します。特に新任マネージャーが着任したタイミングで基準が崩れやすいため、定期的な見直し会を運用に組み込みます。
8.3.3 品質を保つための「検知」と「修正」の仕組み
データ品質は気合では維持できません。運用としては、崩れた瞬間に気づける仕組み(検知)と、直せる導線(修正)をセットで用意します。
- 未更新検知:一定期間活動がない商談、次アクションが空欄の商談を自動抽出
- 矛盾検知:ステージと確度、金額、見込時期の不整合を一覧化
- 差戻しの基準:マネージャーが差戻す条件を明確化し、個人の好みで運用を揺らさない
- 修正の窓口:名寄せ、権限、連携不具合などは営業企画(Sales Ops)に一本化し、現場を迷わせない
最終的に目指すのは、AIが賢くなることだけではありません。「最新の顧客データがあるから、引き継ぎが速い」「会議が短い」「判断がブレない」状態を運用で作り続けることが、AI SFAを組織に浸透させる最短ルートです。
9. まとめ
AI SFAは、AI機能そのものより「AI前提の顧客データ管理」を整えた組織ほど成果が出ます。名寄せ、活動履歴の粒度、商談ステージと失注理由を統一し、メール・電話・Web行動を連携して自動収集を増やすほど現場の入力負担が減り定着します。経営・マネージャーはKPIとダッシュボードを設計し、可視化と予測精度、標準化に接続することが要点です。AI提案が信用されない主因は根拠データ不足なので、品質点検を運用に組み込みましょう。権限設計と個人情報保護法に配慮し、更新責任と営業会議の型まで変えるのが最適解です。
